

HOW are effective Data Products built in Data Science?
aka the Data Product Cycle

TL;DR
Data Science is fundamentally about building Data Products that solve real business needs, not just about machine learning and predictive models. The Data Product Cycle provides a systematic, well-defined process for creating these solutions.
The Data Product Cycle consists of four stages: Diagnosis (defining the problem and assessing data), Development/Implementation (designing and building the solution), Adoption (overcoming obstacles to use), and Evolution (keeping the product relevant).
Each stage of the cycle involves different key players from the Data Science Shop, including Data Scientist Managers and Individual Contributors, Data Engineers, Machine Learning Engineers, and Project Managers, each bringing unique skills to the process.
This structured approach demystifies Data Science, making it a more accessible and reliable tool for businesses. It transforms Data Science from a perceived black box into a systematic method for solving business problems with data and algorithms.
At the core of Data Science are Data Products that solve a need or problem in a business. We’ve discussed WHO builds Data Products, WHERE these Data Products are built and maintained, and WHAT classes of Data Products can a Data Science Shop build. Now we get to explore the different stages in the process to build Data Products (the HOW).
There's a common misconception that Data Science is all about machine learning algorithms and predictive models. While these are certainly important tools in the Data Scientist's toolkit, they don't tell the whole story. Data Science is fundamentally about building Data Products that solve real business needs or problems.
Over time, the discipline has converged on a well-defined process to build these Data Products: the Data Product Cycle. When implemented correctly, this process guarantees that the Data Products built in any Data Science Shop are impactful and aligned with business objectives. The Data Product Cycle provides a clear roadmap that businesses can understand and trust, bridging the gap between complex technical work and tangible business outcomes.
In this post, we'll walk through each stage of the Data Product Cycle, examining the key players involved and the critical steps that transform a business need into a fully-fledged Data Product.
The playbook to build effective Data Products
At the heart of the playbook to create Data Products lies a structured process: the Data Product Cycle. This process consists of four key stages:
Diagnosis
Development/Implementation
Adoption
Evolution
Take a look at this animation to gain intuition about the playbook to build Data Products in any Data Science Shop:
Each stage of the Data Product Cycle involves different members of the Data Science Shop crew, working together to bring a Data Product from concept to reality. Let's break down each stage and see who's involved.
Stage 1: Diagnosis - Defining the Problem
The journey begins with a crucial question: "What problem are we trying to solve?" This stage is the foundation of the entire Data Product Cycle and often doesn't receive enough attention. It's not just about identifying a problem; it's about defining it with crystal clarity and assessing whether a data-driven solution is feasible.

The diagnosis stage involves three critical steps:
Define the problem: This requires a deep understanding of the industry, market, company constraints, and strategic goals. It's about outlining the issue in clear, unambiguous terms that will guide the entire development process.
Identify existing data: All companies have data, but not all of it may be relevant or accessible. This step involves sorting through the inventory of available data sources to find an appropriate one for the use case at hand.
Evaluate data appropriateness: Just having data isn't enough. This step assesses whether the available data is actually useful and appropriate for addressing the defined problem. It's akin to ensuring you have the right fuel for your engine.
Key Players:
Data Scientist Managers: These tech-savvy leaders work closely with the business to identify opportunities and define problems clearly. They bridge the gap between technical knowledge and business acumen.
Data Scientist Individual Contributors (ICs): They dive deep into the data, evaluating its usefulness against the defined problem. Their technical expertise is crucial in determining if the available data can support a viable solution.
Data Engineers: Provide the necessary data for assessment, often pulling from various sources and systems within the organization.
Business Involvement:
Business involvement is crucial at this stage. End-users and their managers should provide detailed input on pain points and problem effects, leveraging their intimate knowledge of daily operations. Simultaneously, C-Suite executives should offer strategic perspective, ensuring the problem definition aligns with company priorities and long-term objectives. This collaborative approach between the Data Science Shop and various business stakeholders ensures a comprehensive and strategically aligned problem definition, setting the foundation for an impactful Data Product.
This stage is critical because it determines whether a Data Product is even feasible. If the problem isn't clearly defined or the data isn't appropriate, the entire project could be derailed before it begins. On the flip side, a well-executed diagnosis stage sets the stage for a successful Data Product that truly addresses business needs.
Stage 2: Development/Implementation - Designing and Building the Solution
Once the problem is clearly defined and data availability confirmed, we move into the heart of the Data Product Cycle: the development and implementation stage. This is where the rubber meets the road, transforming ideas and data into tangible solutions. It's the most technically creative part of the process, often associated with algorithms, machine learning, and artificial intelligence.
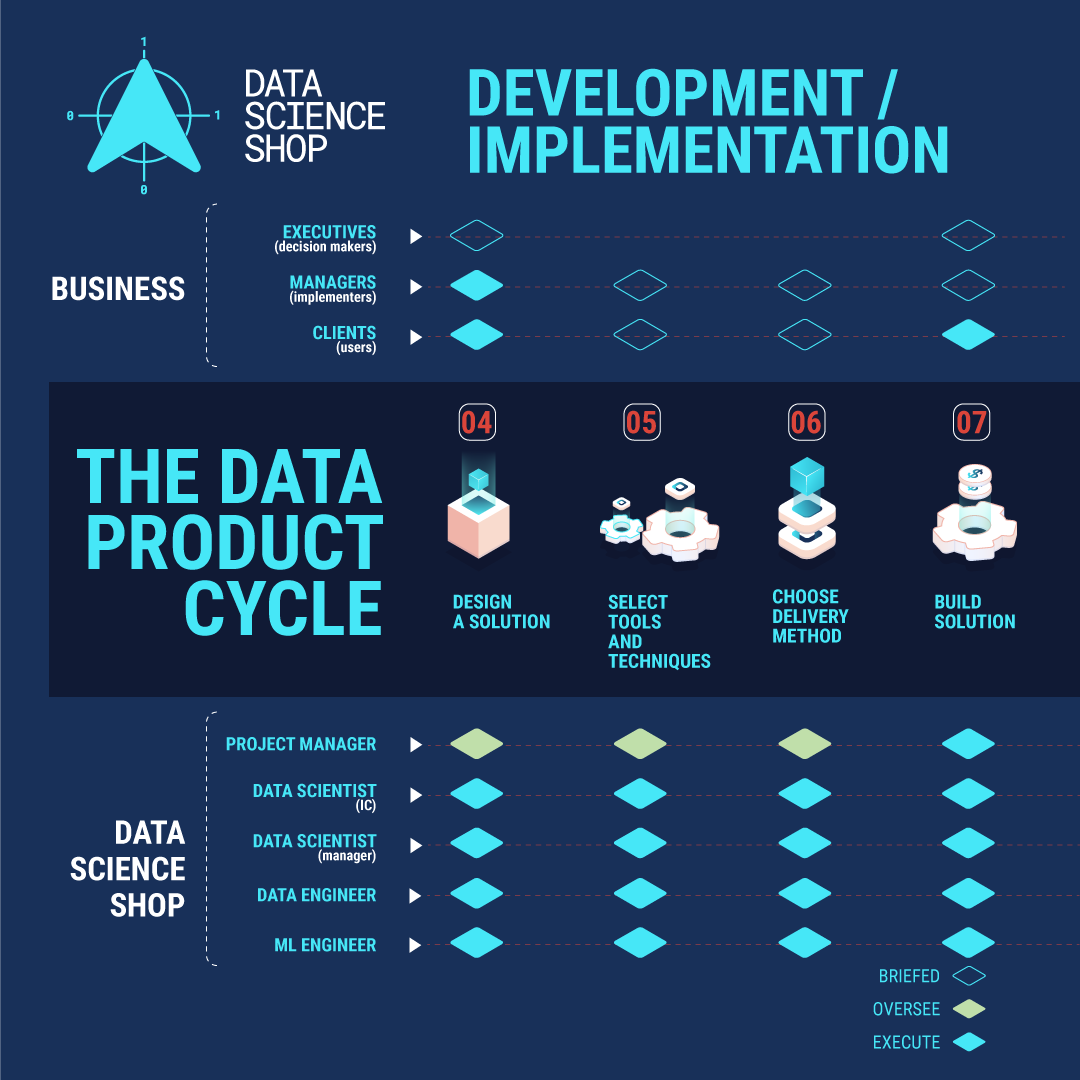
The development/implementation stage involves four critical steps:
Design a solution: This step explores and defines the most appropriate way to solve the problem. It's not just about finding a solution, but finding the best solution given the context. This often involves testing multiple approaches and weighing their pros and cons.
Select appropriate tools and techniques: With the solution design in hand, the team chooses the best tools for the job. This could involve selecting specific algorithms, technologies, or methodologies that best fit the problem and available data.
Decide how the solution will be served: This step considers how the Data Product will be delivered to its users. The team must consider where the users are and how to best fulfill their needs at that "location," whether it's through a dashboard, an API, or some other interface.
Build the solution: This is where all the planning comes together. The team follows two key principles: "start small" and "fail fast." They begin with a small sample of data to quickly assess if the approach works, allowing for rapid iteration if needed.
Key Players:
Data Scientist Managers: These leaders oversee the development process, ensuring that the technical solution aligns with business objectives. They facilitate communication between technical team members and business stakeholders, translating complex concepts in both directions, and provide technical guidance to the team. They also make high-level decisions about approach and resource allocation.
Data Scientist Individual Contributors (ICs): These are the hands-on architects of the solution. They design the technical approach, select and implement appropriate algorithms, and build the initial prototypes. Their deep understanding of statistical and machine learning techniques is crucial for creating effective and innovative solutions.
Data Engineers: They work closely with Data Scientists, ensuring that the necessary data is available and properly structured for the solution. They may also be involved in scaling data pipelines as the solution moves from prototype to production.
Machine Learning Engineers: These specialists help optimize and scale the solution. They take the prototypes built by Data Scientists and ensure they can handle the full scale of data and user load.
Project Managers: They coordinate the overall build process, ensuring that all parts of the solution come together on time and to specification. They also manage communication between team members and stakeholders.
Business Involvement:
During this stage, end-users and managers should provide ongoing feedback, test features, and ensure the product meets their needs. Their input helps the Data Science Shop create a user-friendly and effective solution. C-Suite executives should be consulted at key points, particularly during initial design and pre-build stages, to verify high-level agreement and awareness of the product's capabilities and limitations. This multi-level involvement ensures the Data Product aligns with both user needs and strategic objectives.
The outcome of this stage is a functioning Data Product, ready for adoption by its intended users. However, the journey doesn't end here – the next stages ensure that the product is actually used and continues to evolve with changing needs.
Stage 3: Adoption - Overcoming Obstacles to Use
A Data Product is only valuable if it's used. The adoption stage is crucial in ensuring that the solution doesn't just gather dust but becomes an integral part of business operations. This stage focuses on identifying potential obstacles to adoption and creating strategies to overcome them.

The adoption stage involves two critical steps:
Identify obstacles to adoption: This step involves a comprehensive analysis of potential barriers that could prevent widespread use of the Data Product. These obstacles can be substantive, idiosyncratic, organizational, technical, or human. The team needs to consider factors such as user technical competency, existing workflows, organizational culture, and potential resistance to change.
Craft a strategy to overcome obstacles: Once obstacles are identified, the team develops targeted strategies to address each one. This might involve creating training programs, adjusting the user interface, integrating the product into existing workflows, or developing a change management plan. The goal is to increase the chances that the Data Product is widely used and adopted.
Key Players:
Data Scientist Managers: They lead the efforts to identify obstacles, leveraging their unique position bridging business and technology. Their understanding of both the technical aspects of the product and the business context is crucial in spotting potential adoption issues.
Project Managers: They assist in identifying obstacles and play a key role in developing and implementing strategies to overcome them. Their skills in change management and stakeholder communication are particularly valuable here.
Business Involvement:
In this stage, end-users and managers should collaborate closely with the Data Science Shop to identify potential obstacles and co-create strategies to overcome them. C-Suite executives play a crucial role by providing additional insights, allocating resources, and generating company-wide support for adoption initiatives. This collaborative approach helps address both practical and organizational barriers, increasing the chances of successful integration into business processes.
Stage 4: Evolution - Keeping the Product Relevant
The final stage in the Data Product Cycle is not really an endpoint, but rather the beginning of a new cycle. The evolution stage is all about ensuring the Data Product remains effective over time by identifying unattended business needs and incorporating new features.

The evolution stage involves two main steps:
Uncover unattended business needs: This step involves ongoing engagement with users and stakeholders to identify needs that weren't addressed in the initial product or have emerged since its launch. These could be due to changes in the business environment, shifts in strategic objectives, new regulations, or feedback from users. The team needs to stay attuned to these evolving needs to keep the product relevant.
Incorporate new features into the roadmap: Once new needs are identified, they need to be translated into concrete features or improvements for the Data Product. This involves prioritizing needs, planning development efforts, and creating a roadmap for future iterations of the product.
Key Players:
Data Scientist Managers: They play a crucial role in identifying unattended business needs through ongoing interactions with the business. Their ability to understand both the technical capabilities of the product and the evolving business context is invaluable here.
Project Managers: They take the lead in transforming identified needs into concrete features for the Data Product's roadmap. They plan the development cycles, allocate resources, and manage the overall evolution of the product.
Business Involvement:
For ongoing evolution, end-users and managers should actively provide feedback and identify emerging business needs for future iterations. C-Suite executives should review and provide input on the product roadmap, ensuring alignment with changing business priorities and strategic direction. This collaborative approach to evolution keeps the Data Product relevant, impactful, and in sync with the company's evolving needs and objectives.
The evolution stage is critical for maintaining the long-term value of the Data Product. It ensures that the product doesn't become obsolete as the business environment changes. Moreover, it often kicks off a new iteration of the Data Product Cycle, as newly identified needs may require going back to the diagnosis stage to clearly define the problem and assess data availability.
The Crucial Role of Data Scientist Managers
It's worth highlighting the unique and vital role that Data Scientist Managers play throughout the Data Product Cycle. These professionals combine deep technical knowledge with business acumen, allowing them to:
Identify areas of opportunity for impactful Data Products
Quickly map solutions with a clear vision of what's technically possible
Act as highly technical Project Managers, connecting the dots between business needs and technical possibilities
Their ability to bridge the gap between technical and non-technical aspects makes them instrumental in guiding the entire process of building successful Data Products.
A Well-Defined Playbook for Data Product Success
The Data Product Cycle makes one thing abundantly clear: building impactful Data Products is not a matter of chance or isolated strokes of genius. Instead, it's the result of following a well-defined, structured process—a playbook that guides Data Science teams from initial problem definition to ongoing product evolution.
This playbook—the Data Product Cycle—provides a clear roadmap for turning business needs into effective data-driven solutions. Each stage—Diagnosis, Development/Implementation, Adoption, and Evolution— addresses critical aspects of creating successful Data Products. By adhering to this process, Data Science teams can:
Ensure that Data Products are aligned with real business needs from the outset
Develop solutions that are technically sound and feasible given available data and resources
Proactively address adoption challenges to maximize the impact of their work
Keep Data Products relevant and valuable over time through continuous evolution
The existence of this well-defined process demystifies Data Science, making it a more accessible and reliable tool for businesses. It transforms Data Science from a perceived black box of algorithms and models into a systematic approach for solving business problems with data and algorithms.
By understanding and implementing this playbook, businesses can approach Data Science with confidence. They can trust in a proven process that, when followed diligently, consistently leads to the creation of impactful Data Products. This structured approach not only increases the chances of success for individual projects but also allows for scalable, repeatable Data Science efforts across an organization.
In the end, the power of Data Science lies not just in advanced algorithms or big data, but in the systematic application of a well-defined process to solve real business problems. The Data Product Cycle provides that process—a reliable playbook for turning data into value, time and time again.
Did we spark your interest? Then also read:
WHAT Data Products can Data Science build? to learn about the four classes of Data Products that any Data Science Shop can build
WHO are the people that make Data Science possible? to learn about the specialized technical roles that work in tandem on a Data Science Shop
WHERE are Data Products built (and maintained)? to learn about the technology backbone of Data Products
What is Data Science? to learn more about the practical way to understand Data Science: focus on its outputs (Data Products)
What is the Data Science Shop? to learn more about the roadmap for the operation of Data Science in a business