

WHERE are Data Products built (and maintained)?
a.k.a. the tech environment used by the Data Science Shop

TL;DR
Data Science Shops rely on three main technology architectures: data, computing, and solutions.
Each architecture serves a specific purpose in a Data Product: data for storage and access, computing for data processing, and solutions for user interaction.
The architectures needed depend on the Data Products being built, which should be driven by specific business problems to solve.
We’ve discussed WHO builds Data Products in a Data Science Shop. Now we’ll discuss WHERE these Data Products are built and maintained.
As businesses increasingly rely on data to drive decisions and build products, it's crucial to understand the technological backbone that powers Data Products built in the Data Science Shop. In this post, we'll explore the three key architectures that support Data Products: data architectures, computing architectures, and solutions architectures.
Why do we call them “architectures”?
In the realm of Data Science, an “architecture” refers to the structured framework that organizes and integrates various technological components to support the goals of a Data Science Shop.
Just as a building's architecture provides a structured plan for how different components - like rooms, hallways, and utilities - fit together to create a functional whole, a technology architecture outlines how various digital services and electronic components interact to form a cohesive system to achieve a particular goal, whether that's storing and managing data, processing complex calculations, or interacting with end-users.
This architectural approach allows for a systematic and organized way of thinking about complex technological systems, making it easier to build, maintain, and evolve these critical infrastructures over time.
Take a look at this short animation to get intuition for the tech architectures used in the Data Science Shop:
Data Architecture: the foundation
At its core, a data architecture structures the technologies that make data available to Data Products. Its purpose is to obtain, store, transform, and deliver data. Think of it as the centralized location where data flows to and from.
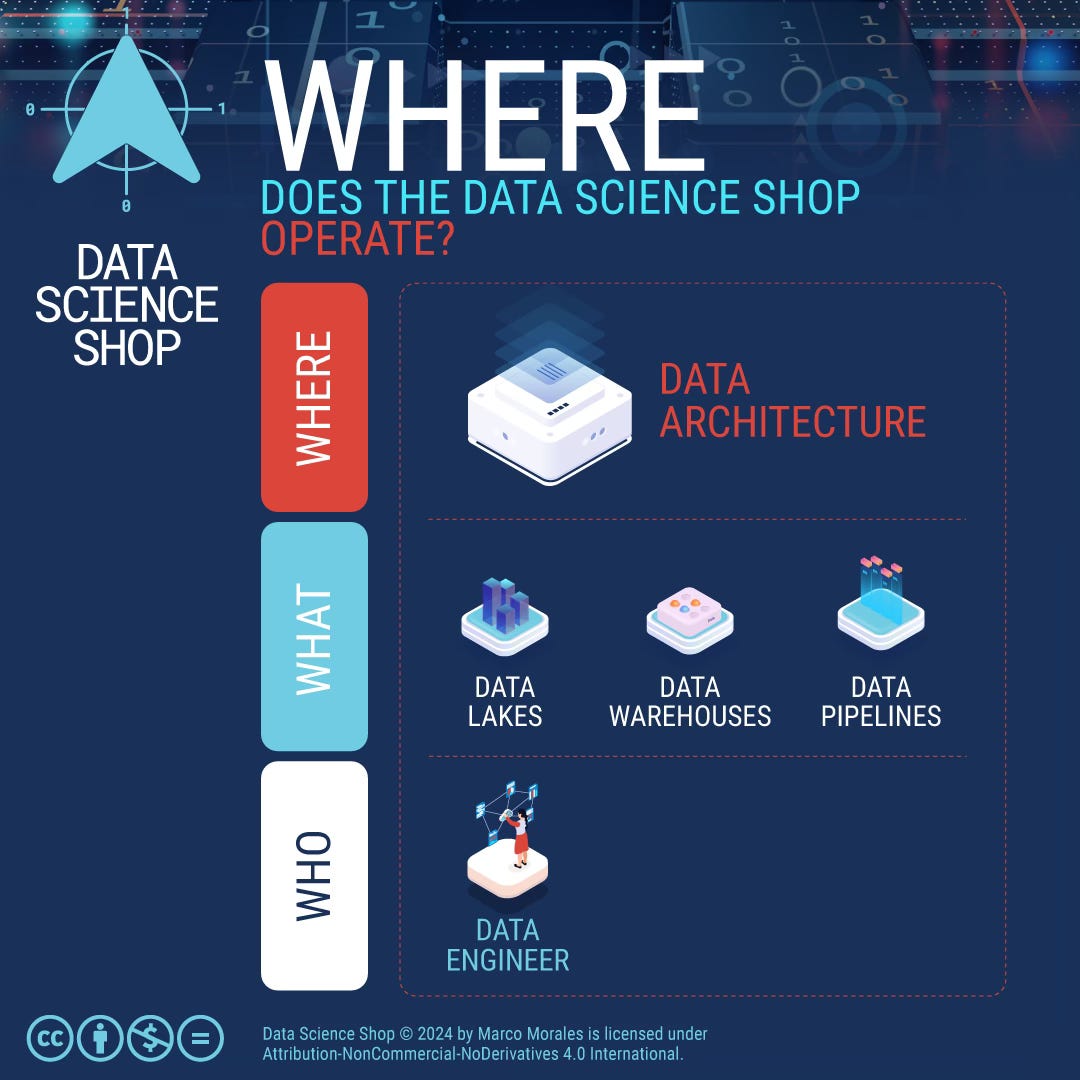
Key components of a data architecture include:
data lakes: repositories where raw data from multiple sources is stored as-is
data warehouses: storage for data that has been transformed into ready-to-use formats (typically including databases of some flavor)
data quality processes: steps to ensure the integrity and consistency of data
data pipelines: automated processes for extracting, transforming, and delivering data
Data Engineers are the key personnel responsible for building and maintaining data architectures.
Computing Architecture: the engine room
A computing architecture structures the computing power that transforms data and extracts value from it. Its purpose is to house, integrate, and maintain the computing resources applied by your Data Products.

Key concepts in computing architectures include:
on-premises vs cloud computing: deciding whether to own physical hardware or rent virtual computing power
parallel computing: using multiple computing cores simultaneously to process data more efficiently
distributed computing: spreading computational tasks across multiple machines or processors
Machine Learning Engineers and Data Scientists are the primary users and maintainers of computing architectures.
Solutions Architecture: the last mile
A solutions architecture structures the technology that supports how a Data Product is made accessible to end users. It organizes and maintains the virtual spaces where Data Products are deployed to interact with humans.

Key elements of solutions architectures include:
applications: software to perform specific tasks
frontends: user interfaces for interacting with data products
containers: software that packages applications with all necessary dependencies to run consistently across different environments
Data Engineers and Machine Learning Engineers collaborate to build and maintain solutions architectures.
An integrated ecosystem
While we've discussed these architectures separately, it's crucial to understand that they form an integrated ecosystem which is the backbone of Data Products. Data flows between them, with outputs from one architecture often serving as inputs to another. This interconnectedness is what allows Data Science Shops to build powerful, end-to-end Data Products.
How do you build these architectures?
It's crucial to remember that, at their core, all three architectures rely on computing power to function. Data architectures use computers to store vast amounts of information. Computing architectures leverage the processing capabilities of computers to perform complex calculations and run sophisticated algorithms. Solutions architectures employ computers to host applications and serve as the interface between Data Products and human users.
In practice, these architectures are often built using services provided by major cloud computing providers such as Amazon Web Services (AWS), Google Cloud Platform (GCP), or Microsoft Azure. These providers offer a wide range of tools and services that can be organized and integrated to form each type of architecture.
For instance, a data architecture might use AWS S3 for data storage, Redshift for data warehousing, and Glue for ETL processes. A computing architecture could leverage GCP's Compute Engine for virtual machines and their AI Platform for machine learning tasks. A solutions architecture might utilize Azure's App Service for hosting web applications and Power BI for data visualization.
Do you need all these architectures?
Not every business needs all three architectures from day one. The architectures you invest in should be determined by the Data Products you aim to build, which in turn should be driven by the specific problems or needs your business is trying to solve.
As with all aspects of Data Science, it starts with a clear definition of the business problem. From there, you can determine which Data Products will best address that problem, and subsequently, which architectures are necessary to support those products.
In conclusion, understanding these architectures is crucial for business leaders looking to leverage Data Science effectively. By grasping the roles of data, computing, and solutions architectures, you'll be better equipped to make informed decisions about your Data Science investments and capabilities.
Remember, the goal isn't to have the most advanced or comprehensive architecture possible, but rather to have the right architecture to support your specific business needs and Data Products. Start with your business objectives and let those guide your technological investments in Data Science.
Did we spark your interest? Then also read:
WHO are the people that make Data Science possible? to learn about the specialized technical roles that work in tandem on a Data Science Shop
What is Data Science? to learn more about the practical way to understand Data Science: focus on its outputs (Data Products)
What is the Data Science Shop? to learn more about the roadmap for the operation of Data Science in a business