

why your Data Product Cycle needs feedback loops
why feedback loops and foresight breed successful Data Products

TL;DR
While the Data Product Cycle might look like a sequential process (diagnosis → development → adoption → evolution), it actually operates through continuous feedback loops where later stages inform and shape earlier decisions.
Development must incorporate adoption foresight by anticipating user needs, workflows, and technical capabilities, ensuring the product is designed to overcome potential adoption obstacles before they arise.
Evolution considerations must be built into initial development through flexible architectures and scalable designs that can accommodate future features and adapt to changing business needs.
Success requires more than technical expertise—it demands a deep understanding of business context, organizational culture, user behaviors, and strategic objectives, making it a truly holistic process rather than a purely technical one.
In a previous post, we discussed the Data Product Cycle as a sequence of steps that lead to building successful Data Products. At first glance, the Data Product Cycle appears to follow a straightforward sequence: beginning with diagnosis, moving through development and implementation, then proceeding to adoption, and finally reaching evolution.
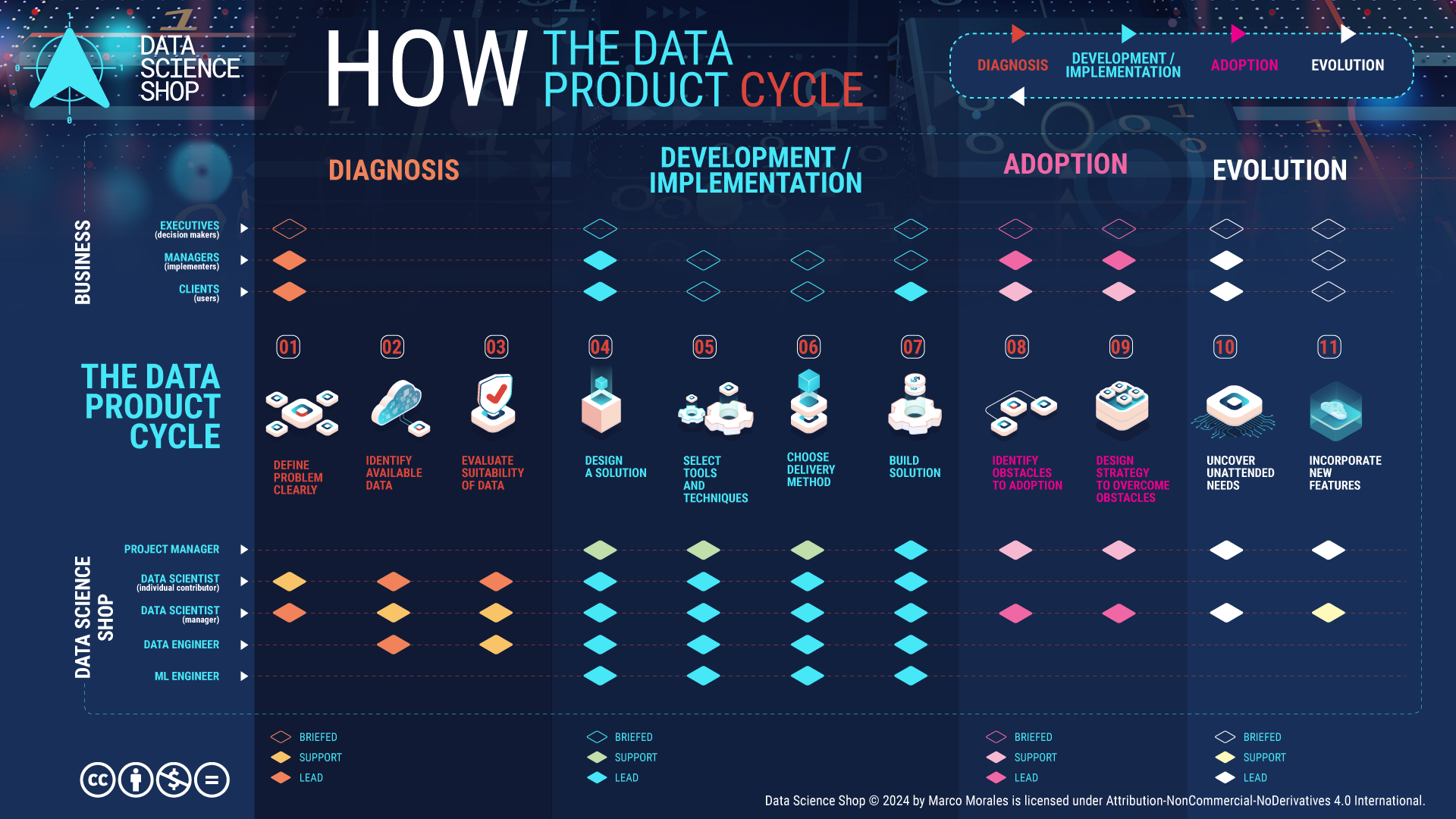
Presenting the Data Product Cycle as a stepwise process is a useful gimmick to explain the method and its stages, but it doesn't capture fully the true complexity and interconnected nature of building successful Data Products. In this post, we’ll explain that feedback loops and foresight make this process non-linear, and that these non-linearities are the secret to building successful Data Products.
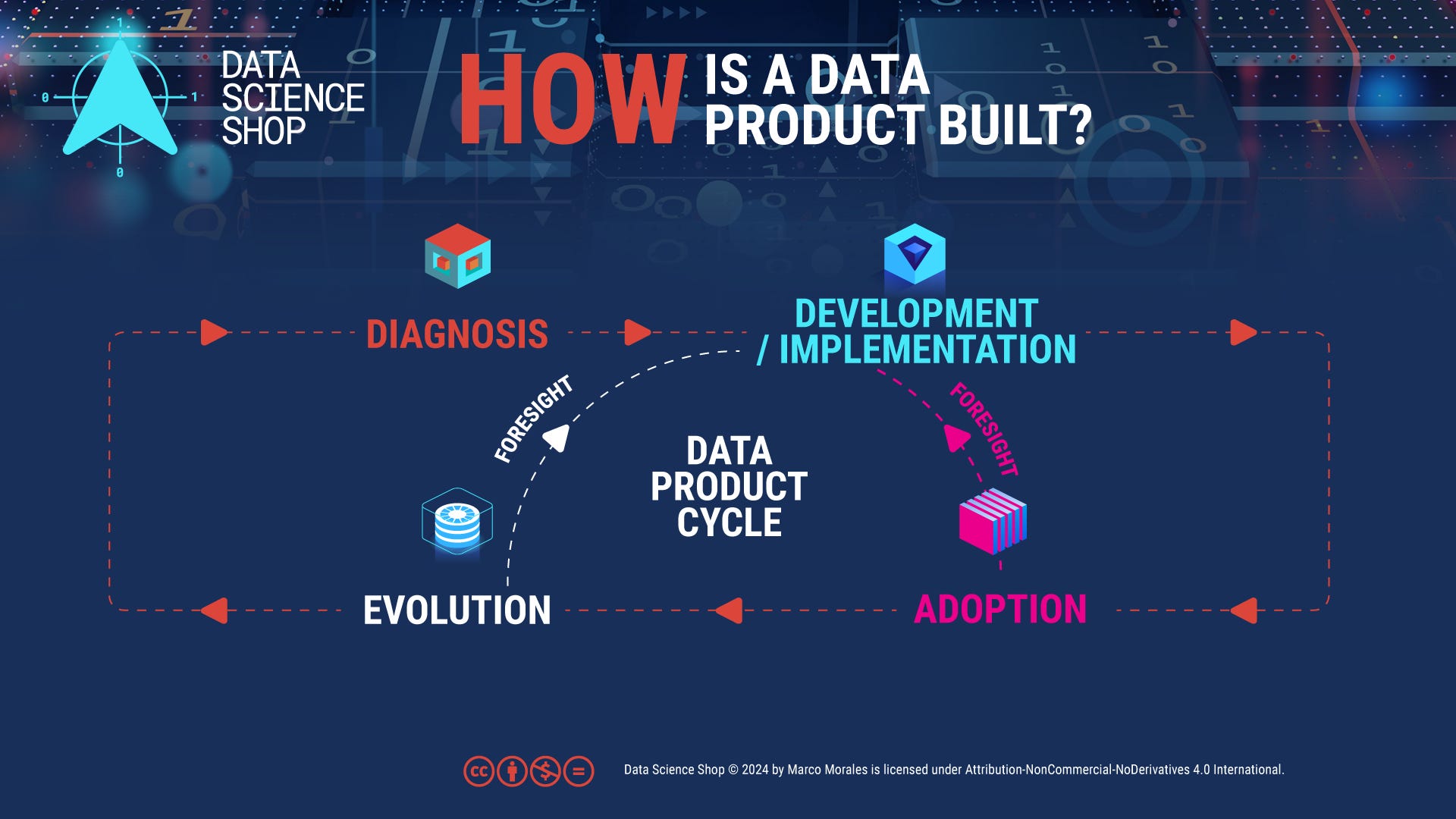
In reality, the development and implementation stage cannot operate in isolation from what comes after. It must be deeply informed by foresight into both adoption and evolution challenges and opportunities.
When it comes to adoption, successful Data Products anticipate and address potential obstacles before they materialize. This means understanding not just what users need, but how they work, their varying levels of technical expertise, and their immediate operational requirements. The development process must consider existing workflows and design solutions that seamlessly integrate into users' daily activities, rather than forcing users to adapt to the product.
Similarly, evolution considerations must be built into the initial design and development phase. This requires creating flexible architectures that can accommodate new features and adapt to changing business needs. The initial version of a Data Product should be developed with future iterations in mind, laying the groundwork for scalability and growth. This forward-thinking approach ensures that the product can evolve alongside the organization, adapting to new strategic objectives and responding to emerging business requirements.
Beyond purely technical skills
This interconnected nature of the Data Product Cycle highlights a crucial point: technical expertise, while essential, is just one piece of the puzzle. Building effective Data Products requires a deep understanding of:
business context and objectives
organizational culture and dynamics
user behaviors and preferences
industry trends and constraints
strategic goals and roadmaps
The development team needs to be as fluent in these business aspects as they are in their technical domains.
The Continuous Feedback Loop
Rather than flowing in one direction, the Data Product Cycle operates through continuous feedback loops where:
adoption insights inform development decisions
evolution requirements shape initial architectures
user experiences guide feature prioritization
business changes trigger design adaptations
This dynamic process ensures that Data Products are not just technically sound, but are also:
readily adoptable by end users
capable of evolving with business needs
aligned with organizational objectives
built for long-term sustainability
Understanding this non-linear nature of the Data Product Cycle is crucial for creating solutions that truly serve their intended purpose and can stand the test of time.
Successful Data Products are not built in isolation or in strict sequential steps, but through a constant interplay of technical development, user needs, and business objectives. This holistic approach, incorporating foresight and feedback throughout the development process, is what distinguishes truly effective Data Products from those that may be technically sophisticated but fail to meet their business objectives or gain user adoption.
Did we spark your interest? Then also read:
HOW are effective Data Products built in Data Science? to learn about the process to build successful Data Products: the Data Product Cycle
WHAT Data Products can Data Science build? to learn about the four classes of Data Products that any Data Science Shop can build
What is Data Science? to learn more about the practical way to understand Data Science: focus on its outputs (Data Products)
What is the Data Science Shop? to learn more about the roadmap for the operation of Data Science in a business